

Le scraping de contenu, aussi connu sous le nom de stitching, est une pratique visant à publier sur un site internet du texte copié, pour ne pas dire volé, d’un autre site. Il s’agit comme vous le savez certainement d’un acte auquel on peut souvent être confronté sur le web, et dont sont friands/allergiques les référenceurs selon la couleur de leur chapeau. Mais aux yeux du géant des moteurs de recherche, qu’en est-il vraiment ?
Les bonnes pratiques selon Google
Des recommandations récentes au sujet du scraping étaient partagées par Google fin 2013 au travers du célèbre responsable de l’équipe en charge de la lutte contre le spam.
Matt Cutts était plutôt clair à ce sujet : aucune valeur ajoutée dans le fait de prendre des morceaux de texte de différents sites web afin de les compiler sur une page, manuellement ou de manière automatisée. A l’inverse, l’exemple de Wikipedia et de son contenu synthétisé tout en mentionnant les sources d’informations, est une pratique acceptée par Google.
Détails des explications dans la vidéo suivante :
Bref, pratiquer le stitching de contenu vous met donc dans une position délicate aux yeux de Google, et vous expose à une pénalité du tout puissant.
Appel de Google à la délation
Comptant sur l’agacement des éditeurs de sites internet qui se voient piller leurs contenus en plus d’éventuellement constater un meilleur positionnement des contenus dupliqués (duplicate content) dans les pages de résultats du moteur, Google vient de mettre en ligne un formulaire de dénonciation nommé Scraper Report.
Si tout se passe comme la firme de Mountain View le souhaite, ledit formulaire sera soumis un certain nombre de fois, lui apportant de précieuses données puisque visiblement elle n’est elle-même pas en mesure de déterminer les sources originales des contenus copiés. Une nouvelle preuve d’impuissance de la part de Google alors même que la société dispose d’une puissance de calcul faramineuse et d’algorithmes très complexes.
Google pris la main dans le sac
La réponse ne s’est pas faite attendre concernant cette pratique de scraping puisque Google se voit rapidement reprocher la copie de passages d’articles justement tirés de Wikipedia pour rapidement répondre aux internautes lors de recherche sous la forme de box dans les pages de résultats.
Est ainsi mise en avant la fonctionnalité d’affichage de définitions par @danbarker, mais il aurait pu en être de même pour de nombreuses données retournées par le Google Knowledge Graph.
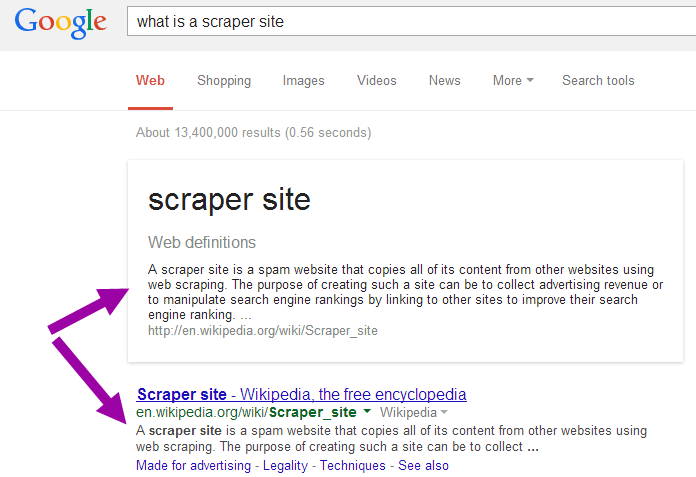
Tel que l’on pouvait s’y attendre, le message posté sur Twitter a depuis été retweeté près de 35 000 fois et mis en favoris plus de 3 600 fois.
Google, l’arroseur arrosé.






{kind=link}